Q.1 What is referential integrity ? What are SQL default value?
To add a DEFAULT constraint to a column in a table when you create it in Oracle, add it to the Create Table statement:
CREATE TABLE tablename (
columnname datatype DEFAULT defaultvalue
);For example, to set a person’s employment status to a default of “Hired”:
CREATE TABLE employee ( id NUMBER, first_name VARCHAR2(200), last_name VARCHAR2(200), employment_status VARCHAR2(20) DEFAULT 'Hired' );We can see on the last line, where employment_status is defined, there is a DEFAULT keyword after the data type. We also specify the default value of ‘Hired’ in single quotes.
Q.2 Explain SQL aggregate function with function
Aggregate Functions : Aggregate functions are those functions in the DBMS which takes the values of multiple rows of a single column and then form a single value by using a query. These functions allow the user to summarizing the data. These functions ignore the NULL values except the count function.
In Database Management System, following are the five aggregate functions:
1. AVG
2. COUNT
3. SUM
4. MIN
5. MAX
AVG Function
This function takes the values from the given column and then returns the average of the values. This function works only on the datatypes, which are specified as numeric in the table.
1 2 3 | Select AVG(Employee_salary) from Employee_Details; |
COUNT Function
This aggregate function returns the total number of values in the specified column. This function can work on any type of data, i.e., numeric as well as non-numeric. This function does not count the NULL values. If we want to count all the rows with NULL values, then we have to use the Count(*) function.
1 2 3 | Select Count(Employee_ID) from Employee_Details; |
SUM Function
This aggregate function sums all the non-NULL values of the given column. Like the AVG function, this function also works only on the numeric data.
1 2 3 | Select SUM(Employee_salary) from Employee_Details; |
MAX Function
This function returns the value, which is maximum from the specified column.
1 2 3 | Select MAX(Cars_Price) from Cars; |
MIN Function
This function returns the value, which is minimum from the specified column.
1 2 3 | Select MIN(Bikes_Price) from Bikes<strong>;</strong> |
Q.3 Define the view in SQL. How can we use views in SQL Queries? What are the materialized view?
Views in SQL are kind of virtual tables. A view also has rows and columns as they are in a real table in the database. We can create a view by selecting fields from one or more tables present in the database. A View can either have all the rows of a table or specific rows based on certain condition.
VIEW in SQL Server is like a virtual table that contains data from one or multiple tables... In a VIEW, we can also control user security for accessing the data from the database tables. We can allow users to get the data from the VIEW, and the user does not require permission for each table or column to fetch data.
A materialized view is a database object that contains the results of a query. The FROM clause of the query can name tables, views, and other materialized views. Collectively these objects are called master tables (a replication term) or detail tables (a data warehousing term).
Q.4 What is transaction management
(a) Explain the following state of Transaction Management
(i) Active
(ii) Partially Committed
(iii) Failed and aborted
(iv) Committed
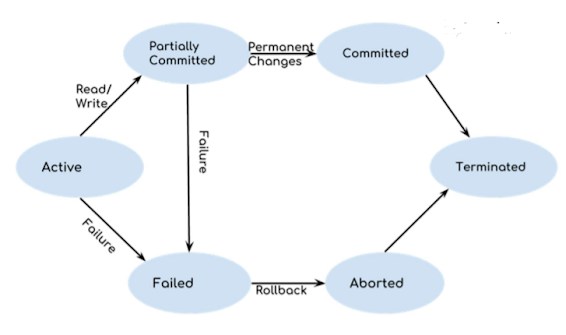
Draw the transaction diagram of Transaction
Transaction management is a logical unit of processing in a DBMS which entails one or more database access operation. It is a transaction is a program unit whose execution may or may not change the contents of a database.
Active State
As we have discussed in the DBMS transaction introduction that a transaction is a sequence of operations. If a transaction is in execution then it is said to be in active state. It doesn’t matter which step is in execution, until unless the transaction is executing, it remains in active state.
Failed and Aborted State
Failed - If a transaction is executing and a failure occurs, either a hardware failure or a software failure then the transaction goes into failed state from the active state.
Aborted - If a transaction fails during execution then the transaction goes into a failed state. The changes made into the local memory (or buffer) are rolled back to the previous consistent state and the transaction goes into aborted state from the failed state.
Partially Committed State
When there are read and write operations present in the transaction. A transaction contains number of read and write operations. Once the whole transaction is successfully executed, the transaction goes into partially committed state where we have all the read and write operations performed on the main memory (local memory) instead of the actual database.
Committed State
If a transaction completes the execution successfully then all the changes made in the local memory during partially committed state are permanently stored in the database. You can also see in the above diagram that a transaction goes from partially committed state to committed state when everything is successful.
Diagram-
Q.5 What do you mean by Con-currency Control? Explain the shared mode lock and exclusive-mode lock.
Concurrency Control in Database Management System is a procedure of managing simultaneous operations without conflicting with each other. It ensures that Database transactions are performed concurrently and accurately to produce correct results without violating data integrity of the respective Database.
Shared mode lock: It is also known as a Read-only lock. In a shared lock, the data item can only read by the transaction. It can be shared between the transactions because when the transaction holds a lock, then it can't update the data on the data item.
Exclusive mode lock - When a statement modifies data, its transaction holds an exclusive lock on data that prevents other transactions from accessing the data. This lock remains in place until the transaction holding the lock issues a commit or rollback.
Q.6 Explain various data types of SQL.
SQL Data Types define the type of value that can be stored in a table column. For example, if we want a column to store only integer values, then we can define its data type as int.
SQL Data Types
- Numeric data types such as int, tinyint, bigint, float, real, etc.
- Date and Time data types such as Date, Time, Datetime, etc.
- Character and String data types such as char, varchar, text, etc.
- Unicode character string data types, for example nchar, nvarchar, ntext, etc.
- Binary data types such as binary, varbinary, etc.
- Miscellaneous data types – clob, blob, xml, cursor, table, etc.
Entity Relationship Model (ER Modeling) is a graphical approach to database design. It is a high-level data model that defines data elements and their relationship for a specified software system. An ER model is used to represent real-world objects.
An Entity is a thing or object in real world that is distinguishable from surrounding environment. For example, each employee of an organization is a separate entity. Following are some of major characteristics of entities.
- An entity has a set of properties.
- Entity properties can have values.
Let’s consider our first example again. An employee of an organization is an entity. If “Peter” is a programmer (an employee) at Microsoft, he can have attributes (properties) like name, age, weight, height, etc. It is obvious that those do hold values relevant to him.
Each attribute can have Values. In most cases single attribute have one value. But it is possible for attributes have multiple values also. For example Peter’s age has a single value. But his “phone numbers” property can have multiple values.
Entities can have relationships with each other. Let’s consider the simplest example. Assume that each Microsoft Programmer is given a Computer. It is clear that that Peter’s Computer is also an entity. Peter is using that computer, and the same computer is used by Peter. In other words, there is a mutual relationship between Peter and his computer.
In Entity Relationship Modeling, we model entities, their attributes and relationships among entities.
are used to perform an operation on input string and return an output string.
Following are the string functions defined in SQL:
- ASCII(): This function is used to find the ASCII value of a character.
Syntax: SELECT ascii('t'); Output: 116 - CHAR_LENGTH(): Doesn’t work for SQL Server. Use LEN() for SQL Server. This function is used to find the length of a word.
Syntax: SELECT char_length('Hello!'); Output: 6 - CHARACTER_LENGTH(): Doesn’t work for SQL Server. Use LEN() for SQL Server. This function is used to find the length of a line.
Syntax: SELECT CHARACTER_LENGTH('geeks for geeks'); Output: 15 - CONCAT(): This function is used to add two words or strings.
Syntax: SELECT 'Geeks' || ' ' || 'forGeeks' FROM dual; Output: ‘GeeksforGeeks’ - CONCAT_WS(): This function is used to add two words or strings with a symbol as concatenating symbol.
Syntax: SELECT CONCAT_WS('_', 'geeks', 'for', 'geeks'); Output: geeks_for_geeks - FIND_IN_SET(): This function is used to find a symbol from a set of symbols.
Syntax: SELECT FIND_IN_SET('b', 'a, b, c, d, e, f'); Output: 2 - FORMAT(): This function is used to display a number in the given format.
Syntax: Format("0.981", "Percent"); Output: ‘98.10%’ - INSERT(): This function is used to insert the data into a database.
Syntax: INSERT INTO database (geek_id, geek_name) VALUES (5000, 'abc'); Output: successfully updated - INSTR(): This function is used to find the occurrence of an alphabet.
Syntax: INSTR('geeks for geeks', 'e'); Output: 2 (the first occurrence of ‘e’)Syntax: INSTR('geeks for geeks', 'e', 1, 2 ); Output: 3 (the second occurrence of ‘e’) - LCASE(): This function is used to convert the given string into lower case.
Syntax: LCASE ("GeeksFor Geeks To Learn"); Output: geeksforgeeks to learn - LEFT(): This function is used to SELECT a sub string from the left of given size or characters.
Syntax: SELECT LEFT('geeksforgeeks.org', 5); Output: geeks - LENGTH(): This function is used to find the length of a word.
Syntax: LENGTH('GeeksForGeeks'); Output: 13 - LOCATE(): This function is used to find the nth position of the given word in a string.
Syntax: SELECT LOCATE('for', 'geeksforgeeks', 1); Output: 6 - LOWER(): This function is used to convert the upper case string into lower case.
Syntax: SELECT LOWER('GEEKSFORGEEKS.ORG'); Output: geeksforgeeks.org - LPAD(): This function is used to make the given string of the given size by adding the given symbol.
Syntax: LPAD('geeks', 8, '0'); Output: 000geeks - LTRIM(): This function is used to cut the given sub string from the original string.
Syntax: LTRIM('123123geeks', '123'); Output: geeks - MID(): This function is to find a word from the given position and of the given size.
Syntax: Mid ("geeksforgeeks", 6, 2); Output: for - POSITION(): This function is used to find position of the first occurrence of the given alphabet.
Syntax: SELECT POSITION('e' IN 'geeksforgeeks'); Output: 2 - REPEAT(): This function is used to write the given string again and again till the number of times mentioned.
Syntax: SELECT REPEAT('geeks', 2); Output: geeksgeeks - REPLACE(): This function is used to cut the given string by removing the given sub string.
Syntax: REPLACE('123geeks123', '123'); Output: geeks - REVERSE(): This function is used to reverse a string.
Syntax: SELECT REVERSE('geeksforgeeks.org'); Output: ‘gro.skeegrofskeeg’ - RIGHT(): This function is used to SELECT a sub string from the right end of the given size.
Syntax: SELECT RIGHT('geeksforgeeks.org', 4); Output: ‘.org’ - RPAD(): This function is used to make the given string as long as the given size by adding the given symbol on the right.
Syntax: RPAD('geeks', 8, '0'); Output: ‘geeks000’ - RTRIM(): This function is used to cut the given sub string from the original string.
Syntax: RTRIM('geeksxyxzyyy', 'xyz'); Output: ‘geeks’ - SPACE(): This function is used to write the given number of spaces.
Syntax: SELECT SPACE(7); Output: ‘ ‘ - STRCMP(): This function is used to compare 2 strings.
- If string1 and string2 are the same, the STRCMP function will return 0.
- If string1 is smaller than string2, the STRCMP function will return -1.
- If string1 is larger than string2, the STRCMP function will return 1.
Syntax: SELECT STRCMP('google.com', 'geeksforgeeks.com'); Output: -1 - SUBSTR(): This function is used to find a sub string from the a string from the given position.
Syntax:SUBSTR('geeksforgeeks', 1, 5); Output: ‘geeks’ - SUBSTRING(): This function is used to find an alphabet from the mentioned size and the given string.
Syntax: SELECT SUBSTRING('GeeksForGeeks.org', 9, 1); Output: ‘G’ - SUBSTRING_INDEX(): This function is used to find a sub string before the given symbol.
Syntax: SELECT SUBSTRING_INDEX('www.geeksforgeeks.org', '.', 1); Output: ‘www’ - TRIM(): This function is used to cut the given symbol from the string.
Syntax: TRIM(LEADING '0' FROM '000123'); Output: 123 - UCASE(): This function is used to make the string in upper case.
Syntax: UCASE ("GeeksForGeeks"); Output: GEEKSFORGEEKS
Types of Cursors in SQL
- Implicit Cursor
- Explicit Cursor
Main components of Cursors
- Declare Cursor: In this part, we declare variables and return a set of values.
- Open: This is the entering part of the cursor.
- Fetch: Used to retrieve the data row by row from a cursor.
- Close: This is an exit part of the cursor and used to close a cursor.
- Deallocate: In this part, we delete the cursor definition and release all the system resources associated with the cursor.
- DDL Trigger
- DML Trigger
- Logon Trigger
1. DDL Triggers
In SQL Server we can create triggers on DDL statements (like CREATE, ALTER, and DROP) and certain system-defined stored procedures that perform DDL-like operations.
Example: If you are going to execute the CREATE LOGIN statement or the sp_addlogin stored procedure to create login user, then both these can execute/fire a DDL trigger that you can create on CREATE_LOGIN event of SQL Server.
2. DML Triggers
In SQL Server we can create triggers on DML statements (like INSERT, UPDATE, and DELETE) and stored procedures that perform DML-like operations. DML Triggers are of two types
After Trigger (using FOR/AFTER CLAUSE)
This type of trigger fires after SQL Server finishes the execution of the action successfully that fired it.
Example: If you insert record/row in a table then the trigger related/associated with the insert event on this table will fire only after the row passes all the constraints, like as primary key constraint, and some rules. If the record/row insertion fails, SQL Server will not fire the After Trigger.Instead of Trigger (using INSTEAD OF CLAUSE)
This type of trigger fires before SQL Server starts the execution of the action that fired it. This differs from the AFTER trigger, which fires after the action that caused it to fire. We can have an INSTEAD OF insert/update/delete trigger on a table that successfully executed but does not include the actual insert/update/delete to the table.
Example: If you insert record/row in a table then the trigger related/associated with the insert event on this table will fire before the row passes all the constraints, such as primary key constraint and some rules. If the record/row insertion fails, SQL Server will fire the Instead of Trigger.
Logon triggers are a special type of trigger that fire when LOGON event of SQL Server is raised. This event is raised when a user session is being established with SQL Server that is made after the authentication phase finishes, but before the user session is actually established. Hence, all messages that we define in the trigger such as error messages, will be redirected to the SQL Server error log. Logon triggers do not fire if authentication fails. We can use these triggers to audit and control server sessions, such as to track login activity or limit the number of sessions for a specific login.
Syntax for Logon Trigger
CREATE TRIGGER trigger_name ON ALL SERVER [WITH ENCRYPTION] {FOR|AFTER} LOGON AS sql_statement [1...n
CREATE TABLE
CREATE TABLE does just what it sounds like: it creates a table in the database. You can specify the name of the table and the columns that should be in the table.
CREATE TABLE table_name (
column_1 datatype,
column_2 datatype,
column_3 datatype
);ALTER TABLE
It changes the structure of a table. Here is how you would add a column to a database:
ALTER TABLE table_name
ADD column_name datatype;SELECT groupingField, AVG(num_field)
FROM table1
GROUP BY groupingFieldTypes of Join statements
The type of join statement you use depends on your use case. There are four different types of join operations:
- (INNER) JOIN: Returns dataset that have matching values in both tables
- LEFT (OUTER) JOIN: Returns all records from the left table and matched records from the right s
- RIGHT (OUTER) JOIN: Returns all records from the right table and the matched records from the left
- FULL (OUTER) JOIN: Returns all records when there is a match in either the left table or right table
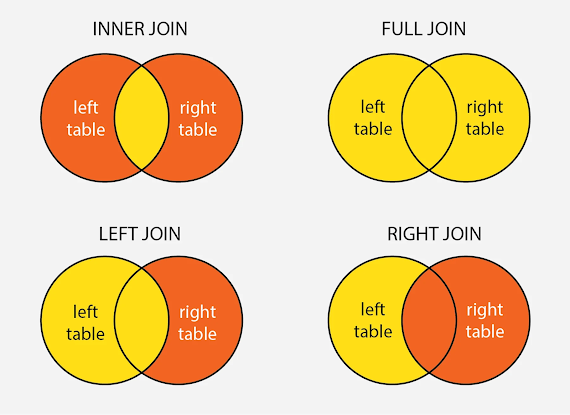
Inner Joins
If you were to think of each table as a separate circle in a Venn diagram, the inner join would be the shaded area where both circles intersect.
The INNER JOIN keyword selects all rows from the tables as long as a join condition satisfies. This keyword will create a result-set made up of combined rows from both tables where a common field exists.
Here is the syntax for an inner join:
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;Left outer Joins
Left join is similar to right join. Left join returns all the rows of the leftmost table and the matching rows for the rightmost table. Below is the syntax:
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;- DBMS stores data as a file whereas in RDBMS, data is stored in the form of tables.
- DBMS supports single users, while RDBMS supports multiple users.
- DBMS does not support client-server architecture but RDBMS supports client-server architecture.
- DBMS has low software and hardware requirements whereas RDBMS has higher hardware and software requirements.
- In DBMS, data redundancy is common while in RDBMS, keys and indexes do not allow data redundancy.
Architecture-
An Oracle database is a collection of data treated as a unit. The purpose of a database is to store and retrieve related information. A database server is the key to solving the problems of information management. In general, a server reliably manages a large amount of data in a multiuser environment so that many users can concurrently access the same data. All this is accomplished while delivering high performance. A database server also prevents unauthorized access and provides efficient solutions for failure recovery.
Oracle Database is the first database designed for enterprise grid computing, the most flexible and cost effective way to manage information and applications. Enterprise grid computing creates large pools of industry-standard, modular storage and servers. With this architecture, each new system can be rapidly provisioned from the pool of components. There is no need for peak workloads, because capacity can be easily added or reallocated from the resource pools as needed.
The database has logical structures and physical structures. Because the physical and logical structures are separate, the physical storage of data can be managed without affecting the access to logical storage structures.
The section contains the following topics:
Oracle Grid Architecture
Application Architecture
Physical Database Structures
Logical Database Structures
Schemas and Common Schema Objects
Oracle Data Dictionary
Oracle Instance
Accessing the Database
Oracle Utilities
Oracle provides several utilities for data transfer, data maintenance, and database administration, including Data Pump Export and Import, SQL*Loader, and LogMiner.
Q.19 Explain the following-
a) Data Abstraction - Data Abstraction is a process of hiding unwanted or irrelevant details from the end user. It provides a different view and helps in achieving data independence which is used to enhance the security of data. The database systems consist of complicated data structures and relations.
b) Mapping Constraints - A mapping constraint is a data constraint that expresses the number of entities to which another entity can be related via a relationship set. It is most useful in describing the relationship sets that involve more than two entity sets.
c) Data Model - The Data Model is defined as an abstract model that organizes data description, data semantics, and consistency constraints of data. The data model emphasizes on what data is needed and how it should be organized instead of what operations will be performed on data. Data Model is like an architect’s building plan, which helps to build conceptual models and set a relationship between data items.
d) Database User - Database users are the one who really use and take the benefits of database. They directly interact with the database by means of query language like SQL. These users will be scientists, engineers, analysts who thoroughly study SQL and DBMS to apply the concepts in their requirement.
e) DBA - A SQL Server DBA (or database administrator) manages the SQL server to successfully store, organize, and access data. SQL Server DBAs analyze an organization's data management, input, and security needs, and help develop tools that support data access and information security.
f) Database Files - Database Files are data files that are used to store the contents of the database in a structured format into a file in separate tables and fields. Database files are commonly used by dynamic websites (eg. Facebook, Twitter, etc.) to store data.
g) Indexing in SQL - A SQL index is a quick lookup table for finding records users need to search frequently. An index is small, fast, and optimized for quick lookups. It is very useful for connecting the relational tables and searching large tables.
h) Commit & Rollback - A COMMIT statement is used to save the changes on the current transaction is permanent. A Rollback statement is used to undo all the changes made on the current transaction. Once the current transaction is completely executed using the COMMIT command, it can't undo its previous state.
i) Aggregation - SQL aggregation is the task of collecting a set of values to return a single value. It is done with the help of aggregate functions, such as SUM, COUNT, and AVG. For example, in a database of products, you might want to calculate the average price of the whole inventory.
j) Order By & Group By - Order by keyword sort the result-set either in ascending or in descending order. This clause sorts the result-set in ascending order by default. In order to sort the result-set in descending order DESC keyword is used.
Group by statement is used to group the rows that have the same value. It is often used with aggregate functions for example: AVG(), MAX(), COUNT(), MIN() etc. One thing to remember about the group by clause is that the tuples are grouped based on the similarity between the attribute values of tuples.
k) Database Manager - Database managers develop and maintain organizations' databases. They create data storage and retrieval systems, troubleshoot database issues, and implement database recovery procedures and safety protocols. Backup and Recovery Management, Data Integrity Management, Database Access Languages and Application Interface, Database Communication Interface.
l) Purpose of DBMS -
Purpose - It is a collection of programs that enables the user to create and maintain a database. In other words, it is general-purpose software that provides the users with the processes of defining, constructing and manipulating the database for various applications.
M) Data Independence - Data independence is the type of data transparency that matters for a centralized DBMS. It refers to the immunity of user applications to changes made in the definition and organization of data. Application programs should not, ideally, be exposed to details of data representation and storage.
Q.20 Write a program in PL/SQL to find out largest between three numbers.
Declare a number; b number; c number;Begin dbms_output.put_line('Enter a:'); a:=&a; dbms_output.put_line('Enter b:'); b:=&b; dbms_output.put_line('Enter c:'); c:=&C;if (a>b) and (a>c) then dbms_output.put_line('A is GREATEST'||A);elsif (b>a) and (b>c) then dbms_output.put_line('B is GREATEST'||B);else dbms_output.put_line('C is GREATEST'||C);end if;End;Q.21 Difference between DDL and DML in DBMS.
DDL:
DDL is Data Definition Language which is used to define data structures. For example: create table, alter table are instructions in SQL.
DML:
DML is Data Manipulation Language which is used to manipulate data itself. For example: insert, update, delete are instructions in SQL.
Difference between DDL and DML:
| DDL | DML |
|---|---|
| It stands for Data Definition Language. | It stands for Data Manipulation Language. |
| It is used to create database schema and can be used to define some constraints as well. | It is used to add, retrieve or update the data. |
| It basically defines the column (Attributes) of the table. | It add or update the row of the table. These rows are called as tuple. |
| It doesn’t have any further classification. | It is further classified into Procedural and Non-Procedural DML. |
| Basic command present in DDL are CREATE, DROP, RENAME, ALTER etc. | BASIC command present in DML are UPDATE, INSERT, MERGE etc. |
| DDL does not use WHERE clause in its statement. | While DML uses WHERE clause in its statement. |
Q.22 What is Query language? Write down the difference between Procedural query language and Non-procedural query language.
A query language is a specialized programming language for searching and changing the contents of a database.
Difference between Procedural and Non-Procedural language:
| Procedural Language | Non-Procedural Language |
|---|---|
| It is command-driven language. | It is a function-driven language |
| It works through the state of machine. | It works through the mathematical functions. |
| Its semantics are quite tough. | Its semantics are very simple. |
| It returns only restricted data types and allowed values. | It can return any datatype or value |
| Overall efficiency is very high. | Overall efficiency is low as compared to Procedural Language. |
| Size of the program written in Procedural language is large. | Size of the Non-Procedural language programs are small. |
| It is not suitable for time critical applications. | It is suitable for time critical applications. |
| Iterative loops and Recursive calls both are used in the Procedural languages. | Recursive calls are used in Non-Procedural languages. |
Q.23 what do you mean by data model. Explain the Relational model and entity relationship model
The Data Model is an abstract model that organizes data description, data semantics, and consistency constraints of data. The data model emphasizes on what data is needed and how it should be organized instead of what operations will be performed on data. Data Model is like an architect’s building plan, which helps to build conceptual models and set a relationship between data items.
Relational Model - Relational Model (RM) represents the database as a collection of relations. A relation is nothing but a table of values. Every row in the table represents a collection of related data values. These rows in the table denote a real-world entity or relationship. In the relational model, data are stored as tables.
Entity Relationship Model - An entity relationship model , also known as an entity relationship diagram (ERD), is a graphical representation that depicts relationships among people, objects, places, concepts or events within an information technology (IT) system.
{kind=link}
0 Comments